
Hôm nay trên Threads city lan truyền một vụ đáng chú ý:
– paste prompt vào ChatGPT, kêu nó tạo ảnh, sản phẩm tạo ra giống người thật đến mức “không biết trùng mặt ai không nữa.”
Nghe vui, nhưng vấn đề phía sau nó không vui.
OpenAI ghi rõ trong chính sách: khi bạn dùng ChatGPT gói cá nhân (Free, Plus, Pro), nội dung bạn gửi lên, bao gồm cả ảnh, có thể được dùng để train model. Mặc định tính năng này BẬT. Nghĩa là nếu bạn không tự tay vào Settings > Data Controls > tắt “Improve the model for everyone”, thì mọi thứ bạn upload đều có thể trở thành dữ liệu huấn luyện.
Thêm một chi tiết ít người biết: kể cả khi bạn đã tắt training, nhưng nếu bạn bấm thumbs up hay thumbs down phản hồi bất kỳ câu trả lời nào, toàn bộ cuộc hội thoại đó vẫn có thể được dùng để train.
Ảnh AI tạo ra giống người thật không có nghĩa nó copy mặt ai cụ thể. Nhưng khi hàng triệu người upload ảnh cá nhân, ảnh gia đình, ảnh con cái lên ChatGPT mỗi ngày mà không tắt training, thì dữ liệu đó đang đi đâu, phục vụ ai, bạn không kiểm soát được.
Vài việc nên làm ngay:
– Vào Settings, tắt “Improve the model for everyone”.
– Không upload ảnh CMND, căn cước, ảnh nhạy cảm lên AI
Nhớ: tắt training chỉ áp dụng cho hội thoại mới, những gì đã gửi trước đó thì đã trễ.
Công cụ miễn phí thì bạn là sản phẩm. Câu này cũ nhưng chưa bao giờ sai.
Ảnh dưới là prompt và kết quả do mình test. Khá ảo.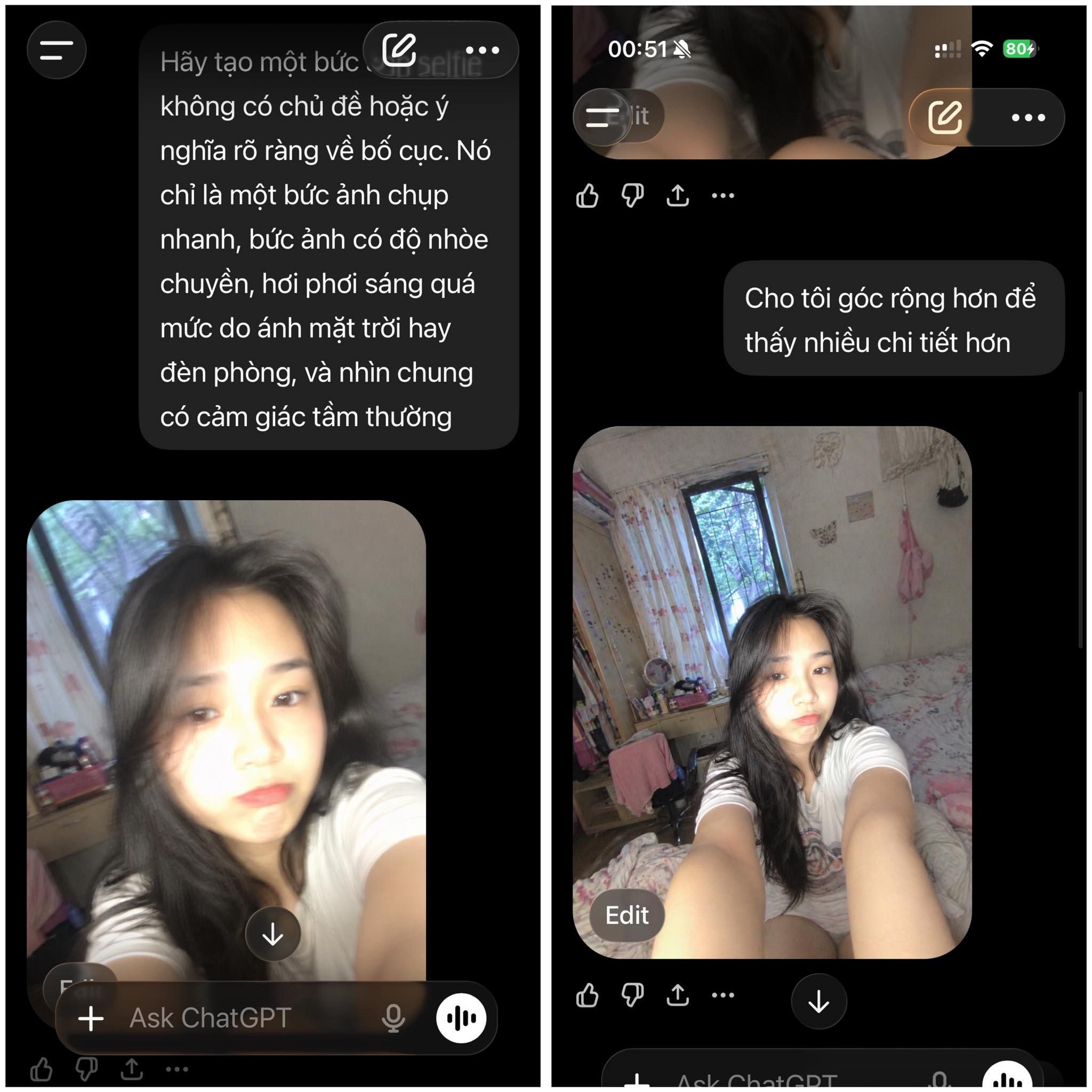
#nhannguyensharing






